slam中涉及到的一些知识点,做个总结,尽量结合实际项目或代码,持续更新增加。。。
光流法跟踪特征点
以vins中的光流前端为例子。在slam前端用光流法的优点是计算效率高,适用于实时性要求较高的场景(相较于特征点法而言),当然现在有些特征点法速率也不错,但其精度和速率总是难以两全,虽然SIFT计算复杂,但其精度、稳定性等仍然在层出不穷的传统特征点提取算法中保持优越。
光流法有较强的假设性:
- 亮度恒定,投影在图像中的同一点随着时间不会变化。
- 小运动,就是随着时间的变化不会引起位置的剧烈变化,这样灰度才能对位置求偏导。
- 空间一致,一个场景上邻近点投影到图像上也是邻近点,且邻近点速度一致,这是对于Lucas-Kanade 光流法特有的假设,因为光流法基本方程约束只有一个,而要求
, 方向上的速度有两个未知量,假设了邻域运动一致,就可以联立多个方程。
虽然现在有些光流法通过金字塔或者亮度质心等来去除或者松弛这些约束,但这样一来和特征点法有何差异呢,也是个计算效率和准确率的取舍问题。
VINS中采用的是LK金字塔光流法
LK光流法
相机的不同帧图像是随时间变化的,那么在
这个方程中有两个未知数,因此至少需要两个方程才能解,根据前面的假设,认为在邻域内像素和该像素具有相同的运动状态,可以构建
特征点法跟踪(以ORB为例)
什么是ORB特征点
特征点一般由关键点和描述子两部分组成。ORB特征点是在FAST特征点的基础上加入了方向信息,对应的在描述子中加入了方向的描述。(Oriented FAST关键点和Streered BRIEF描述子)两部分。
ORB特征选取策略:
- 在图像中选取某个像素
,其灰度值为 。 - 设定一个阈值
,以 为圆心,半径为3个像素的16个像素点上比大小。 - 如果16个像素点上有连续
个灰度大于或小于 ,则确定为关键点,在ORB-slam中 - 实际中为了加速,通常选取第1、5、9、13个像素点的灰度值来比较,有大于等于三个像素点满足条件
则认为中心像素点为一个关键点。
为了保证特征点的尺度不变性和计算方向,引入了图像金字塔和灰度质心法。简要记一下灰度质心法,计算关键点为圆心指定半径中园的灰度质心,圆心到质心方向即为关键点方向。
图像的矩定义为:
那么分别在坐标轴
对应圆形区域内所有像素的灰度值总和为:
那么图像的质心为:
同时,可以计算出关键点的旋转角度为:
然后就可以将图像按照
描述子 Steered BRIEF
BRIEF是一种二进制编码的描述子,在ORB-SLAM2中它是一个256bit的向量。以下是计算方法:
- 为减少噪声干扰,先对图像进行高斯滤波。
- 以关键点为中心,取一定大小的图像窗口
,在窗口内随机选取一对点,比较二者像素的大小,进行如下二进制赋值。 - 在窗口中随机选取
,(在ORB-slam2中是256)对随机点,重复上面的步骤,得到一个256维的二进制描述子。
对于选点,在ORB-slam2中采用固定的选点模板,是一个256x4个值组成的数组,每行的4个值表示一对点的坐标。
而增加了旋转方向的Steered BRIEF描述子则是先将此区域旋转(或者通过下面的矩阵找到旋转前的点在图像中的位置)。
特征点均匀化
- 根据总的图像金字塔层级和待提取的特征点总数,计算图像金字塔中每个层级需要提取的特征点数量。
- 划分格子(在ORB-slam2中固定尺寸为30像素x30)
- 对每个格子提取角点,如果初始的FAST角点阈值没有检测到角点,则降低阈值,再提取一次,若还是没有角点,则不在这个格子提取。
- 用四叉树均匀地选取角点。
特征点匹配
在特征点匹配中(单指帧与帧之间的匹配),这里不同于光流法的直接跟踪,特征点的匹配需要去对应帧全图寻找匹配点,很耗费计算资源,因此需要采取一定的策略加速匹配。在ORB-slam2中是在匹配点对应的匹配帧的对应位置一定范围内进行匹配,并且为了加速,还将匹配区域划分为一个一个的网格,遍历网格寻找匹配点。
为了减少误匹配,ORB-slam2中还采用了方向一致性检验,简而言之就是将源匹配点和目标匹配点的主方向做差,然后统计这个差的直方图分布,选取排在前三的直方图格子,其余在外的就认为是误匹配点对。
词袋模型匹配
这个一般直接调用库,后面再细究。
vins初始化过程中的陀螺仪偏置标定
对于窗口内连续两帧土
vins中的IMU预积分
首先给出imu的测量模型,包括加速度和角速度的测量值模型:
给定两个图像帧
为了避免重复积分,因此要采用预积分算法来避免。
首先将公式(1-2)中的参考坐标系从世界坐标系转换到本地坐标系
为了处理方差的传播,定义了一个关于旋转四元数的误差扰动模型真值=测量值+误差(扰动模型)。
由此完成了IMU预积分测量值的推导,但是要将IMU预积分用到非线性优化中,需要建立线性高斯误差状态递推方程,由高斯系统的协方差推导方程的协方差矩阵,并求解对应的雅可比矩阵。
由此可以给出在
对于式(1-7)的推导,一个一个的推导一下:
- 先对
, , 这三个简单的推导一下,根据定义有: 为了更好理解推导过程,将式(1-4)推导的预积分誊抄一下: 对预积分的 求微分有:
由此就很好理解
- 然后就是推导
。 的理论值,即不考虑存在噪声 和 时为: 。 实际测量值,即考虑噪声时为: 则有: - 接下来推导
,首先需要推导 理论值,即不考虑噪声 和 : 的真实测量值为: 根据导数性质有: 第二个等式的括号表明的是对整体求导,第三个等式是 前导后不导,后导前不导的导数性质,第四个等式就是将前面理论值代进去。
那么根据真实测量值的等式和导数性质求得的等式,就可以得到一个等式:
根据导数的定义有:
李群和李代数
三维旋转矩阵构成了特殊正交群
每个李群都有相对应的李代数,因为李群这种代数作为优化变量在做运算时候会引入额外的约束,使得优化没有那么方便(如旋转矩阵本身是正交且行列式为1,在整个优化过程中不仅要考虑优化结果,还要保持旋转矩阵本身的性质)。因此引入李代数来接触这类约束。
引出李代数:
对于任意的旋转矩阵
那么有:
对等式两边求导有:
整理一下有:
那么可以看出
假设在
对于李代数
关于
卡尔曼滤波
卡尔曼滤波建立在线性代数和隐马尔可夫模型(当前状态量之和前一时刻状态量有关)上。
状态方程:
是作用在 上的状态变换模型(作用在状态量上的) 是作用在控制器上的输入控制模型(u_k表示k时刻的输入) 是过程噪声,并假设符合均值为零,协方差矩阵为 的多元正态分布。
其中
观测方程:
初始状态以及每一时刻的噪声
算法逻辑
卡尔曼滤波是一种迭代的估计,利用上一时刻状态的估计值和当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史值。
卡尔曼滤波分为预测和更新两个部分。预测是指利用上一时刻的状态估计,对当前时刻状态做出估计。在更新阶段用当前状态观测值优化在预测阶段得到的预测值。
则预测和更新的过程如下:
- 预测
预测步骤中,根据上一时刻的状态和输入的控制量,预测当前时刻的状态。这是一个估计值,没有考虑当前时刻的观测值。估计值的误差协方差矩阵是通过上一时刻的误差协方差矩阵和系统噪声协方差矩阵的到。
- 更新
更新步骤是根据当前时刻的观测值和预测值,计算出当前时刻的状态估计量。状态估计值的误差协方差矩阵是通过预测步骤得到的误差协方差矩阵,观测噪声协方差矩阵和卡尔曼增益计算得到的。
上面预测和更新的总共五个方程为卡尔曼滤波的核心公式
为了使更新步骤的公式看起来更加简洁,首先计算下面三个量:
公式推导
状态估计误差
其中 表示在k-1时刻对 的估计值。状态估计方程为: 观测估计误差
观测估计方程
那么根据上述方程可以定义两个重要的误差协方差矩阵(用于判别估计的精准性):
状态误差协方差矩阵
观测误差协方差矩阵
卡尔曼滤波的目的是得到一个基于误差能够不断修正的迭代估计表达式,其具体形式应该如下:
对于状态误差协方差矩阵和观测误差协方差矩阵的推导后面再添加
扩展卡尔曼滤波
状态转移方程和观测方程
预测和更新
不再推导了,直接给出结论
- 参数:包括状态转移矩阵
、测量矩阵 、过程噪声协方差矩阵 和测量噪声协方差矩阵 - 超参数:初始状态估计
和初始协方差矩阵
后面再补充具体线性化和雅可比推导
误差状态卡尔曼滤波
ESKF中通常将原状态变量称为名义变量,ESKF中的状态变量为误差状态变量,两者之和为真值。
这里以
假设ESKF的真值状态为
ESKF的状态方程
上面知道了真值状态量的状态方程,下面就推导误差状态量的状态方程,首先定义误差状态量为:
现在来推导误差状态量对时间的导数(模仿前面的真值状态量的导数)。
对于误差变量的平移、零偏和重力公式,都很容易直接求出相对于时间的导数表达式:
- 误差状态量的旋转项 对旋转式两侧求时间的导数有:
这里对 求导等于对一小角度旋转向量 的指数映射求导,用到了李代数里面的知识点。
该式子中的
因此第一个式子可以写为:
- 误差状态的速度项 由前面已知速度真值的微分形式
与真值状态和误差状态的关系 。同样的对速度的误差形式两端求导数,先对左侧,就是对 求导数,由前面的推导已经有: 公式的第一行到第二行可以看到是将 、 、 转换为了名义状态量+误差状态量的形式。
第二行到第三行用了
第三行到第四行忽略了
第四行到第五行则用了叉乘符号交换顺序后需要加负号的特性。
然后再对等式右边
离散时间下的ESKF运动学方程
名义状态变量的离散时间运动学方程为:
粒子滤波
引出:KF针对线性高斯系统,EKF用于求解非线性高斯系统。但是对于非线性非高斯系统是无法得到解析解的,只能通过采样的方式(蒙特卡洛法)来近似求得所有概率的值,由此引出粒子滤波算法。
蒙特卡洛采样法
以抽样的方法去近似求得后验概率
重要性采样基本原理
当
但是在计算过程中,在每次迭代过程中都需要计算
序列重要性采样
序列重要性采样主要是为了找到
首先看分子:
同理分母作为提议分布,是自定的,其递推形式也是根据定义的分布来推导。由此权重递推问题得到简化。
重采样
但是这样会带来一个退化问题,在经过几次迭代以后,很多粒子的权重都变得很小,只有少数的权重比较大,这样使得大量计算浪费在对估计后验概率分布几乎不起作用的粒子上,为此克服此问题最直接的方法是增加粒子,但这样会造成计算的增加。因此一般采用一下两种途径:
- 选择合适的重要性概率密度函数(提议分布)
- 在序贯重要性采样后,用重采样的方法。
重采样的思路是:既然权重小的粒子不起作用,那就不要了。但要保持粒子数目不变,就得用新的粒子来取代它们。找到新粒子最简单的方法就是将权重大的粒子多复制几个,至于复制多少?根据权重大的粒子里自身权重所占比例去分配,也就是权重最大的粒子复制最多。
最小二乘问题的求解
什么是最小二乘问题
在slam中就是根据状态量值和测量值来构建一个误差函数,然后求解在误差最小时对状态量的最优估计。比如下面这样一个误差函数:
然后最小二乘就是求解这样一个误差函数得到状态量
最小二乘问题的求解
给定遮掩一个最小二乘问题求解的定义,找到一个
损失函数的泰勒展开:假设损失函数是可导且平滑的,因此二阶展开为:
最小二乘问题的求解方法-迭代下降法
对于线性最小二乘(即损失函数为线性函数),可以采用直接法求解。
思想就是找到一个下降方向使损失函数随
- 找到代表下降方向的单位向量
。 - 确定下降步长
假设
最速下降法
从下降的方向的条件可知:
牛顿法(适用于最优值附近)
在局部最优值
牛顿法加阻尼项
简单来说就是在牛顿法对损失函数泰勒展开中增加了一个阻尼项,然后对这个增加了阻尼项的函数做最小化。
将损失函数的二阶泰勒展开记作:
非线性最小二乘基础(为后续高斯牛顿法和LM法铺垫)
这里是残差函数
另外,容易得到
高斯牛顿法
高斯牛顿法就是求上面那个公式的一阶导为零的时候的解(从结果上看用信息矩阵来近似海森矩阵的牛顿法)。
Levenberg-Marquardt(LM)方法
就是在求解过程中加入了阻尼因子,如下:
阻尼因子的作用 定性分析来说就是增大阻尼减小步长,拒绝本次迭代。或者减小阻尼增大步长,加快收敛,减少迭代次数,LM更加接近高斯牛顿法。
阻尼因子的更新策略 是通过比例因子来决定的,比例因子计算公式为:
其中: Marquardt提出了一种更新策略: 而g2o和ceres采用的是Nielsen(尼尔森)策略:
滑动窗口
舒尔补
点云配准
4PCS算法(粗配准)
是一种类RANSAC算法的点云配准算法。
- 对于待匹配点云集合
,先从点云 中选取三个点,再根据一定原则选取另一个足够距离的点,组成共面四点基。 - 然后根据仿射不变从点集
中提取在一定距离 内可能与前面那个共面四点基相符的4点集合 。 - 分别计算每个集合和共面基的刚性变换关系。
- 在
中选取多组共面基,重复上述步骤 - 当测试一组刚性变换有足够多的对应点则完成匹配,并选择此组刚性变换为最佳变换。
K-4PCS算法(粗配准)
比上面的4PCS算法多了降采样和关键点检测步骤。
- 利用体素滤波器对点云进行下采样,然后采用标准的3D harris或者3D DoG算法进行3D关键点检测。
- 这里就通过前面的4PCS算法进行匹配,不过就是选择关键点,而不是共面基。
SAC-IA算法(粗配准)
输入:源点云
输出:
- 在
中随机采样 个点,保证它们之间的最小距离大于 - 对每一个采样点在
通过K-D树最邻近搜索寻找一组FPFH特征相似的点,并从这些相似点中任选一个点作为对应点 - 对上面步骤中每一批点对确定一个变换,并用如下公式度量变换的质量(其中
为变换后第i组对应点之间的误差),返回最小误差 对应的变换
将对象模板与点云对齐(粗配准)
简而言之即用一个模板点云,在目标中进行匹配,例如用一个人脸的深度点云图来匹配目标点云中人脸的位置和方向。
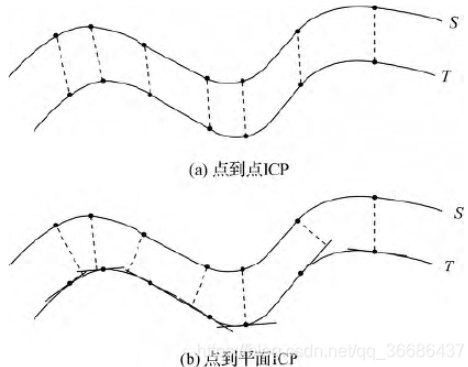
点到点的ICP算法(精配准)
输入:两帧原始点云,变换的初始估计,迭代停止的标准
输出:变换矩阵,变换后的修正点云
ICP算法步骤: - 对点集
终止条件:1、最大迭代次数。2、搜索对应点对的最大距离。3、收敛标准,估计点云变化不再变化(当前变换和上次变换的差值之和小于用户设定的阈值)。4、找到的解(误差平方和小于用户自定义的阈值)
KD-ICP算法(精配准)
简单来说就是将点云构建为kd树结构,寻找目标点小于预定欧氏距离范围内的点,这里用kd树加速了最邻近搜索,这样可以快速剔除配准错误的点,然后采用ICP进行精确匹配,加速了整个匹配过程。
双向KD-ICP算法:就是对两个点云都构建kd树,正向反向搜索确定一对一的匹配关系,不像KD-ICP找到的是一对多的关系。 - 分别构建
双向kd-tree虽然搜索时间是kd-tree的两倍,但算法的迭代时间得到了减少,特别适合数据量大的点云模型。
3DSC+ICP融合配准算法(精配准)
就是先提取3DSC描述子进行粗匹配,然后根据粗匹配结果用ICP进行精确匹配
点到面的ICP算法
点到面ICP采用最小源点云中点到目标点云对应点所在平面的距离作为配准准则
IMU标定
低精度MEMS惯性器件的误差一般分为两类:系统性误差和随机误差。系统误差本质是能够找到规律的误差,可以实时补偿掉,包括常值偏移、比例因子、轴安装误差。随机误差一般指噪声,无法找到合适的关系函数去描述噪声,一般采用时间序列分析方法对零点偏移的数据进行误差建模分析,也可以用卡尔曼滤波算法减小随机噪声的影响。
系统性误差
IMU系统误差主要包括三部分,噪声(Bias and Noise)、尺度因子(Scale)、轴偏差,考虑这些偏差的测量模型可以表示为:
一般估计方法为对采集的数据用非线性优化的方法,估计出待求解参数。
随机误差-ALLAN方差校准
主要包括量化噪声、角度随机游走、零偏不稳定性、角速度随机游走、速率斜坡和正弦分量。
通过ALLAN方差得到一个ALLAN曲线,根据不用斜率段可以分析不同成分的噪声。ALLAN方差可以看作通过调节ALLAN方差滤波器带宽,对功率谱进行细致分隔,从而辨别出不同类型的随机过程误差。
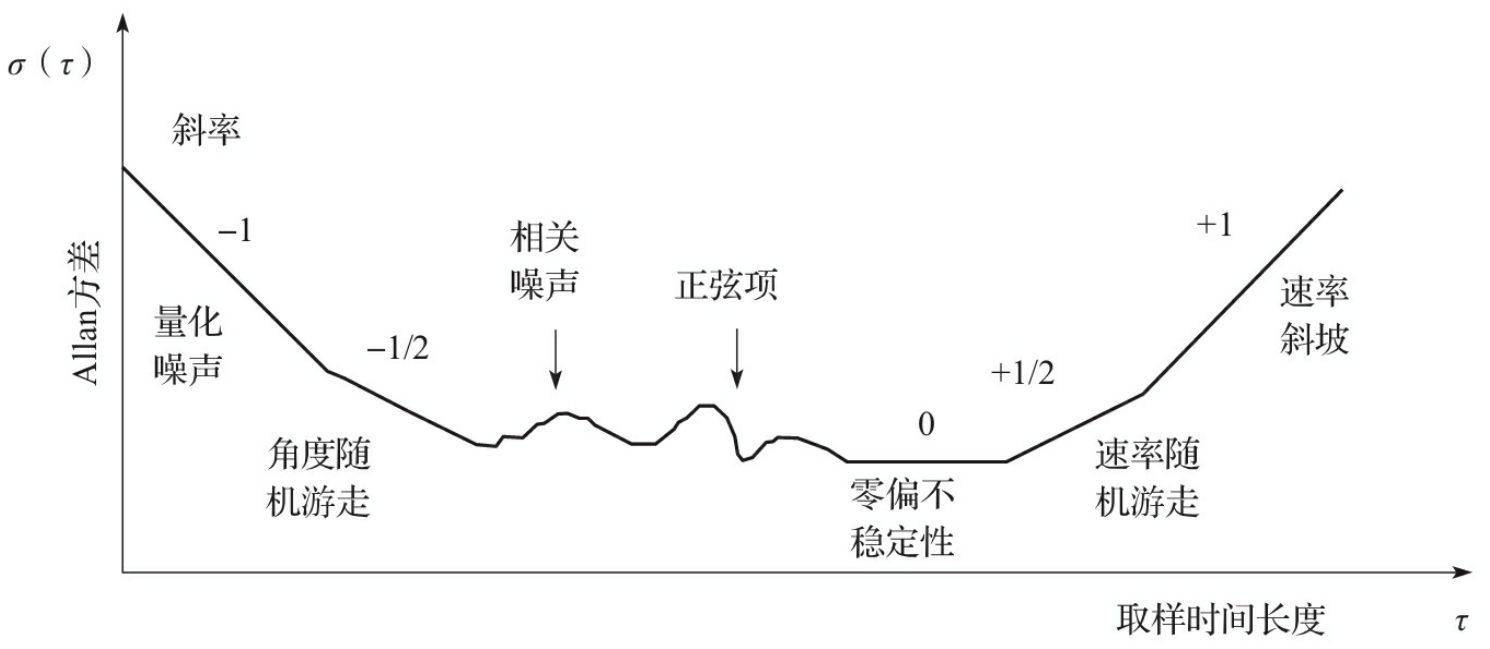
对量化噪声、角度随机游走、零偏不稳定性、速率随机游走、速率斜坡这五个噪声建模有:
如何计算ALLAN方差: - 在采集样本中设定采样周期
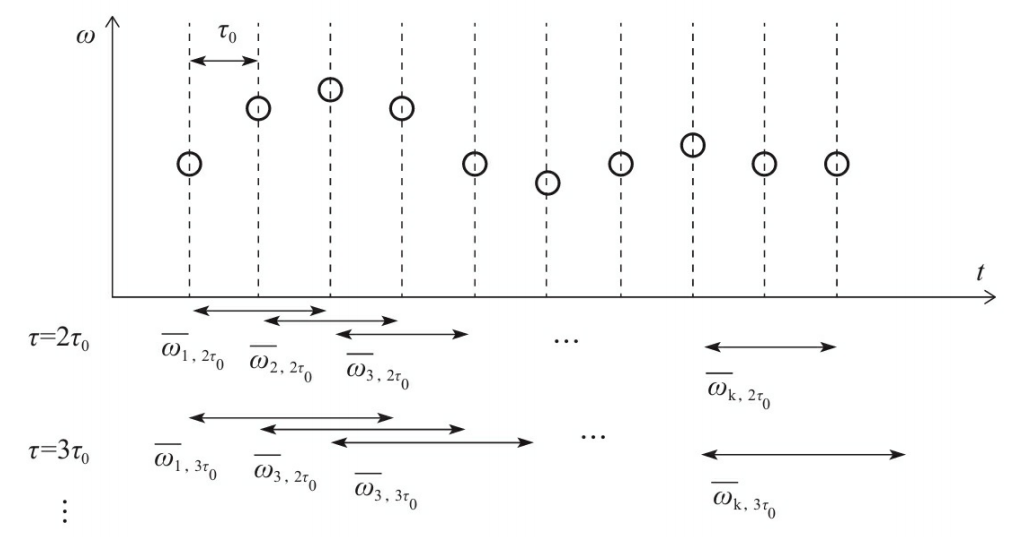
- 对同一大小窗口
下相邻两个窗口片段均值求差值,然后对所有差值求均方差 - 依次求出所有
值下的方差 ,并绘制曲线
相机内参标定
一般简单概括为一下四个步骤: - 从图像中提取标定板角点,根据不同标定板类型有不同的角点提取方法 - 对于一个非线性优化方法,需要有个不错的初值。对于主点坐标
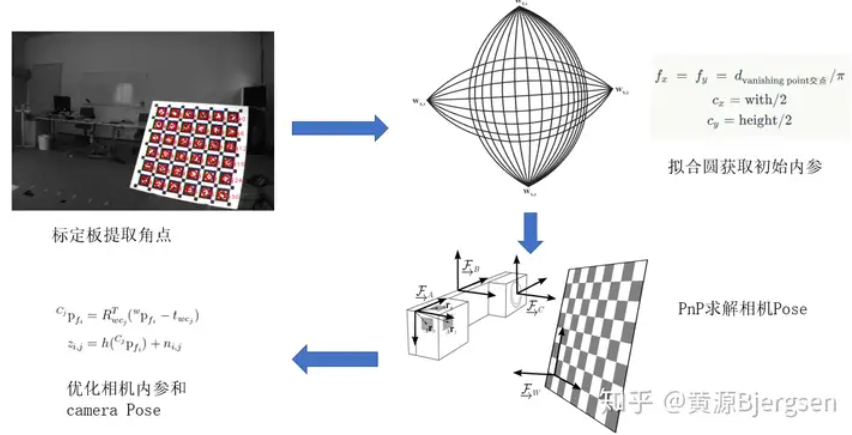
对于带畸变参数的标定,一般先构建畸变参数的非线性优化,求解畸变参数,再求解相机内参,然后再融合同时优化畸变参数和相机内参。
畸变矫正
径向畸变:镜头的折射引起的畸变,主要包含桶形畸变和枕形畸变。这个畸变程度和像素点距中心的距离
切向畸变:相机镜头和图像传感器平面由于安装误差导致不平行引入的畸变。
于是引入参数


